
Learning from Imbalanced Classes
This post gives insight and concrete advice on how to tackle imbalanced data.
This post gives insight and concrete advice on how to tackle imbalanced data.

On July 13th we welcomed the Open Data Science Conference meetup series to our HQ—our speaker talked about thinking critically about the size of your data.

This post will show architects and developers how to set up Hadoop to communicate with S3, use Hadoop commands directly against S3, use distcp to perform transfers between Hadoop and S3, and how distcp can be used to update on a regular basis based only on differences.

This post gives you a quick overview of the new structured streaming feature in Spark 2.0, illustrating why it’s an exciting addition.

A team of our data scientists recently won 2nd place in Confluent’s Kafka Hackathon. In this post, explore their project—streaming EEG data and visualizing it.
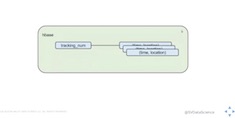
In this post, we cover what’s needed to understand user activity, and we look at some pipeline architectures that support this analysis.

This post walks you through a simple failure recovery mechanism, as well as a test harness that allows you to make sure this mechanism works as expected.

In this post we share some links to interesting work being done with social media data.
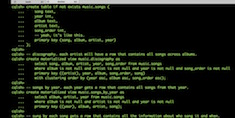
In this screencast, Principal Engineer and Cassandra committer Gary Dusbabek provides an overview of Materialized Views.