
Q&A: On Being Data-Driven
December 7th, 2017
Editor’s Note: This is a transcript of the Q&A portion of a webinar we held earlier this year, called “What it Means to be Data-Driven”. These questions have come up repeatedly at other talks we’ve given on the topic, and so we decided to present them in blog format in the hopes that they will reach and help even more people. Have additional questions? Leave them in the comments below.
Q: What is the minimum viable platform infrastructure I need to play with data? It’s not easy to transition an entire organization’s infrastructure, and in order to convince people to do that, I need to show a proof of concept first.
A: We’ve never heard of a successful data project that went “zero to hero” overnight. It’s true that you need to move through stages, proving what works. You can create a minimum viable environment from anything, just on your laptop or in a couple of virtual machines in the cloud. That itself isn’t the issue—it’s when you get to architecting and building out the larger thing that risk comes in. Once we get past a proof of concept stage, we do what we call a “steel thread.” That steel thread is a valuable business case, the solution to an important problem. For example, it could be personalizing product pages for customers.
As we build out the parts of an ultimate platform, it’s necessary to solve that one problem first. By orienting your build-out around this steel-thread business case, you create both immediate business value and reusable parts that can support additional use cases.
Q: How do I talk to my leadership about experimentation and failure in a way that gets them on board?
A: Focus on the problems that data can solve. For example, saying “You have this business problem, I think that this data has the answer.” Also, you could point out that there is power in the data, but it is unknown and so you need to manage the risk (through experimentation platforms). The A/B testing used in products and web analytics shows where experimentation has been industrialized to prove optimization and worth. So there’s lots of external proof you can look to.
Q: What processes do you put around an iteration loop to set expectations and keep it orderly?
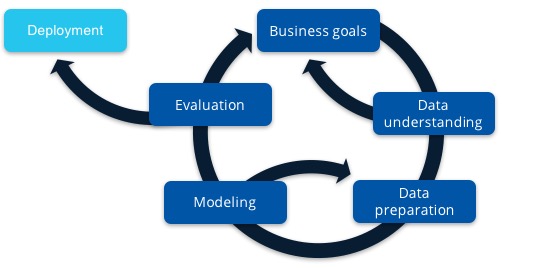
A: This is the foundation of our agile data science process, as detailed in this blog post by CTO John Akred. We create “epics”—which are large themes that we want to investigate in our data science explorations—and then we work in a cadence of two-week sprints. At the beginning, we work on one of the epics—for example, seeing whether we can predict the buying behavior of customers. Then we break down what we need to do into what are called “stories” in agile methodology. After looking into that for two weeks, we check back with business stakeholders and tell them what we’ve learned so far. Agile is part of how we ensure that business has regular buy-in.
Q: Would you consider data engineering as part of the Cloud, DevOps, or Open Source section of the Experimental Enterprise?
A: Data engineering is really about constructing the architecture that supports data science on top of it, so in many ways you could say the collective of data engineering has everything below the data science brick. It’s a lot of plumbing and software engineering work.
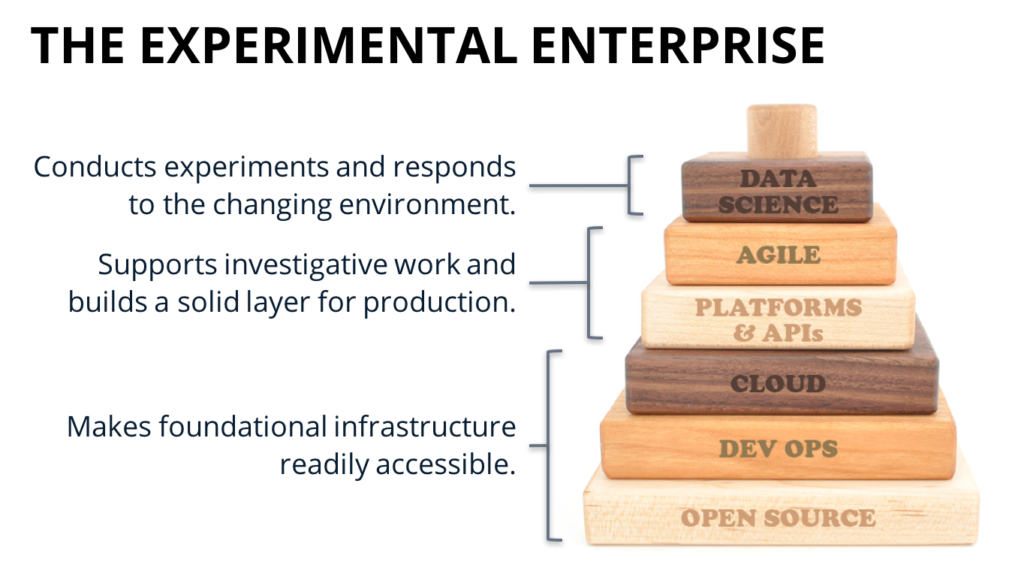
It’s worthwhile to reiterate that we do believe in the close association of data engineers and data scientists. It’s not uncommon for data scientists to build models in R, for example, and when one of these models is thrown over to the engineers it needs to be re-implemented in Java for production purposes. This system is suboptimal for a few reasons:
- It’s slow.
- It’s open to mistakes in translation.
- It’s very difficult for data scientists to dig in and figure out what’s going on if things don’t go according to plan.
So we believe that both disciplines must work together, and also that tools like Spark are useful, in that they blur the lines and allow both sides to use the same systems for development and production.
Q: It sounds so simple when you lay out the idea of doing things with data, but I don’t even know where to start inside of my traditional organization. What are the immediate, concrete steps I can take to work toward the things you’re recommending?
A: The best way to spread data-driven thinking through an organization is by solving a problem. That is famously how Intuit retooled from being a financial services company to being a data company—it was one department arguing that data could help business problems, and a manager supporting that. In other words, demonstrating success is what moves data projects forward.
So in terms of concrete steps, I’d point to the following questions. (You can do this big, or you can do this small.) What are the problems you want to solve? What data do you have? Can you combine those things to take a step toward solving a small burden or problem? You may need to get resources, you may need to persuade people, and so on—but it’s really as simple and as complicated as this. It’s simple emotionally; it’s complicated because people are involved and data is everywhere.



