
Mind Reading: Using Artificial Neural Nets to Predict Viewed Image Categories From EEG Readings
Winning at DeepGram Hackathon | June 29th, 2017
How can artificial neural nets help in understanding our brain’s neural net?
On the weekend of March 24–26, YCombinator-backed startup DeepGram hosted a deep learning hackathon. The weekend-long event included speakers and judges from Google Brain, NVIDIA, and Baidu. My colleague, Dr. Matt Rubashkin, also participated and you can read about his project here. I chose to work on one of the datasets suggested by DeepGram: EEG readings from a Stanford research project that predicted which category of images their test subjects were viewing using linear discriminant analysis. Winning Kaggle competition teams have successfully applied artificial neural networks on EEG data (see first place winner of the grasp-and-lift challenge and third place winner of seizure prediction competition). Could a neural net model do better on this Stanford data set?

The six major categories of images shown to test subjects were: human body, human face, animal body, animal face, natural object, and man-made object. Example images from each category are shown at right.
Dataset description and representation
The Stanford research paper includes a link to download their dataset. You can follow along in my Jupyter notebook posted on GitHub.
According to the dataset’s accompanying README text file, the EEG sensor they used on their test subjects was this device. The device had 124 electrodes—each collecting 32 readings at 62.5 Hz every time a person was shown an image. Below is a plot of the EEG reading from electrode 1 in the first trial—where each trial simply means an image was shown to a test subject for about half a second—on the first test subject (out of ten).
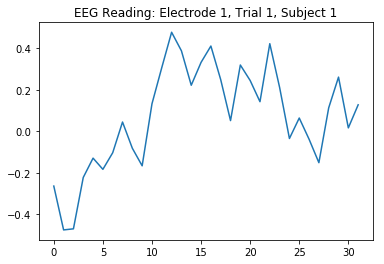
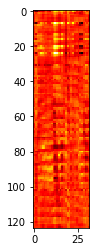 Now, imagine arranging the EEG readings such that each trial is a 32 x 124 heatmap (see figure at right).
Now, imagine arranging the EEG readings such that each trial is a 32 x 124 heatmap (see figure at right).
Convolutional neural networks (CNN) have performed very well in computer vision tasks in recent years. Might a CNN be trained on this heatmap representation be able to accurately guess which category of image each test subject viewed?
One of the first things to check before training a classifier is to check the data for class balance (which my colleague, Dr. Tom Fawcett, explains here). In short, if one of the image categories was overrepresented in the data, our neural network would be trained to become biased towards that overrepresented category and potentially misclassify the rarer categories. Fortunately, the dataset is well-balanced.
Model architecture
After some experimentation, I eventually settled on a single 2D convolutional layer followed by a dense layer section. Dropout was added to reduce overfitting. More convolutional layers and pooling didn’t seem to help. But don’t take my word for it. I encourage you to try different architectures and hyperparameters. For example, try different activation functions other than the rectified linear unit (ReLU) that is commonly found in deep learning and used in my model. Or, try different sizes of dense layers and convolutional layer filters, kernels, and strides.
Model training
The first nine test subjects’ EEG readings were used as the training set while the tenth test subject’s readings were set aside as the holdout set. In order to gauge whether your model generalizes well to new people, you must NOT include the readings from at least one of the test subjects in the training data. In the Stanford paper, it’s not clear whether they did so as part of their cross validation strategy. However, they did perform ten-fold cross validation, which should be done with the CNN model in order to more confidently gauge its true accuracy.
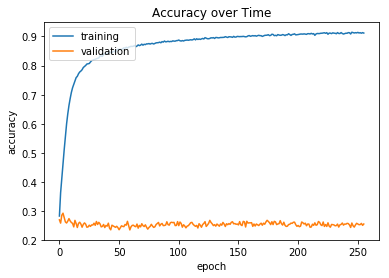
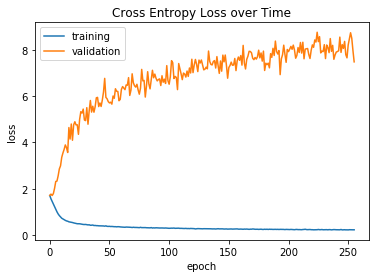
The two plots below show the training history of the CNN model’s accuracy and categorical cross entropy loss on the test data set as well as the holdout data set (labeled as “validation” in the plots). While the model overfits the training data to reach over 90% accuracy, the accuracy on the holdout set stays steady at approximately 25%, which is still better than randomly guessing one of the 6 categories (16.67%). The categorical cross entropy loss for the holdout set worsens, however. Due to the time constraints in the hackathon, I did not have time to do cross-validation nor did I have time to experiment with different CNN architectures that would result in holdout set accuracies as good as the training set, so I leave those as an exercise to the reader.
Model quality
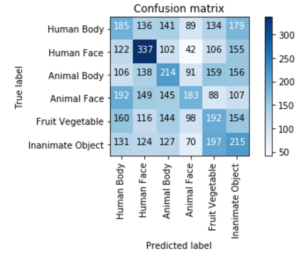 Measuring accuracy and cross entropy loss are rough estimates of model performance. Plotting the confusion matrix, shown below, gives more detail on how many of the CNN’s predictions actually match the original true image category that the holdout test subject saw. The CNN does a good job of categorizing EEG readings of human faces, which may be a byproduct of our natural abilities and may be no surprise to any neuroscientists and psychologists reading this that humans recognize human faces very well.
Measuring accuracy and cross entropy loss are rough estimates of model performance. Plotting the confusion matrix, shown below, gives more detail on how many of the CNN’s predictions actually match the original true image category that the holdout test subject saw. The CNN does a good job of categorizing EEG readings of human faces, which may be a byproduct of our natural abilities and may be no surprise to any neuroscientists and psychologists reading this that humans recognize human faces very well.
Further work
This blog post has shown that a CNN is a promising approach for classifying EEG data. Perhaps you can do even better. Some suggestions to try:
- Cross-validation
- Different numbers of layers, hyperparameters, dropout, activations
- Test whether your neural network can generalize to the same person(s) in the future, not just to new people
- Finer-grained classification with the 72 image subcategories
Final thoughts
There’s a certain irony in using brain-inspired constructs to study the brain itself! Could deep learning be a key component in building future brain-computer interfaces like Elon Musk’s Neuralink or Facebook’s proposed brain interface?
Acknowledgements
Thanks again to DeepGram for organizing the hackathon and awarding me a prize (NVIDIA Titan X GPU). And thanks to fast.ai’s Jeremy Howard for his wonderful deep learning class. I highly recommend it to software engineers who wish to learn the basics of deep learning quickly.



