
Why Notebooks Are Super-Charging Data Science
March 22nd, 2016
Here at SVDS, our data scientists have been using notebooks to share and develop data science for some time. Notebooks have everyone excited, and are here to stay. More than just making data scientists happy, they also bring advantages in productivity and collaboration. So what is it that makes notebooks better than working with data science tools, such as R or Python, alone?
What are notebooks?
As their name suggests, notebooks carry the metaphor of paper books forward. They’re pretty much your old lab book from high school science, but with a Harry Potter twist. Like photographs in the Daily Prophet, the code in a notebook can be executed and results displayed as part of the page.
Notebooks can be saved as files, checked into revision control just like code, and freely shared. They run anywhere, thanks to their browser-based user interface. Though the most influential notebook, Jupyter, has its origins in the Python programming language, it now supports many other programming languages, including R, Scala, and Julia. The popular Apache Spark analytics platform has its own notebook project, Apache Zeppelin, which includes Scala, Python, and SparkSQL capabilities, as well as providing visualization tools.
There is little limit to what can be done with a notebook. As well as the data science work you might expect, such as manipulating and graphing data, we’ve used them for sharing work on analytical tasks such as motion detection in video. In this post I’ll take a look at why we’re seeing notebooks everywhere.
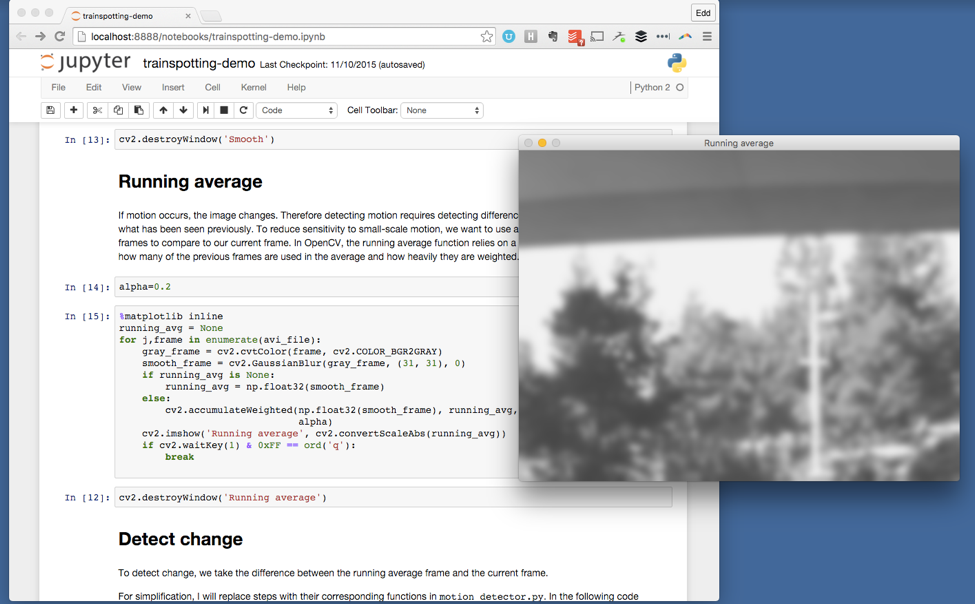
A Python notebook in Jupyter being used to explain and demonstrate motion detection in video, part of our Caltrain Rider project
Why are notebooks so exciting?
There are three key areas that explain the continued popularity of notebooks.
Collaboration
Previous solutions for collaboration in data science have been built on top of a closed world of tooling, constraining collaboration inside a particular platform. They were also rather limited—often restricted to sharing just SQL queries. Today’s data science is conducted on a much faster-moving open technology platform, where analyses might use a multiplicity of tools such as Python, Hadoop, and Spark. Contemporary data science also tends to happen hand-in-hand with engineering, where the tooling for collaboration has made leaps forward in the last decade, in source control, issue management, project tracking, and more. Notebooks, being essentially files, can live happily in a world of source control, such as Github, and be easily shared around an organization. What’s more, the document nature of a notebook makes it easy to add prose and diagrams that travel around with the code itself, enabling explanation and interpretation to stay with the analysis.
Easy access to resources
Notebooks give data scientists easy access to both data and computing power. As notebooks are hosted in the browser, there is no need to ship data to the data scientist’s computer to let them do work. This means that they can operate directly against a cluster storing all the data they need, making notebooks ideal for conducting big data analyses. Notebooks give data scientists access to scalable computing clusters, without requiring them to become distributed systems programmers or verse themselves in devops. Data now doesn’t travel outside of the cluster, and can be governed with similar access controls to other internal resources.
Building blocks for the future
By enabling an open source, extensible, approach to incorporating functionality, notebooks provide a foundation that can fully leverage the power of the browser and the network. If there’s a JavaScript library for it, you can bring it into a notebook front end, and if there’s a cloud resource with a corresponding Jupyter kernel, you can use it in analyses. It will now take a lot less work to create applications that build on these capabilities; for example, to give non-analyst colleagues in the business the ability to explore data and simulations.
Data science for the era of open source and cloud
Notebooks are changing the way data science teams work, thanks to the combination of the rich web browser user interface, open source, and scale-out cloud big data solutions. Not only do we now spend less time in accessing, sampling and transporting data, but we gain great features for collaboration, sharing, and explanation. Given the rapid evolution and innovation in notebooks, we’ve only seen the start of where this will lead—it’s unthinkable that future analytic platforms won’t include and extend these powerful collaborative capabilities.
How are you using notebooks? We’d love to hear your tips, or if there are situations where notebooks didn’t work for you.
Edd talks about the business advantages of notebooks, as well as other hot data technologies such as Spark and Kafka at Strata and Hadoop World San Jose. Go here to sign up to receive the slides.