
Streaming Video Analysis in Python
Trainspotting series | October 13th, 2016
Editor’s note: This post is part of our Trainspotting series, a deep dive into the visual and audio detection components of our Caltrain project. You can find the introduction to the series here.
At SVDS we have analyzed Caltrain delays in an effort to use real time, publicly available data to improve Caltrain arrival predictions. However, the station-arrival time data from Caltrain was not reliable enough to make accurate predictions. In order to increase the accuracy of our predictions, we needed to verify when, where, and in which direction trains were going. In this post, we discuss our Raspberry Pi streaming video analysis software, which we use to better predict Caltrain delays.
Platform architecture for our Caltrain detector
In a previous post, Chloe Mawer implemented a proof-of-concept Caltrain detector using a webcam to acquire video at our Mountain View offices. She explained the use of OpenCV’s Python bindings to walk through frame-by-frame image processing. She showed that using video alone, it is possible to positively identify a train based on motion from frame to frame. She also showed how to use regions of interest within the frame to determine the direction in which the Caltrain was traveling.
The work Chloe describes was done using pre-recorded, hand-selected video. Since our goal is to provide real time Caltrain detection, we had to implement a streaming train detection algorithm and measure its performance under real-world conditions. Thinking about a Caltrain detector IoT device as a product, we also needed to slim down from a camera and laptop to something with a smaller form factor. We already had some experience listening to trains using a Raspberry Pi, so we bought a camera module for it and integrated our video acquisition and processing/detection pipeline onto one device.
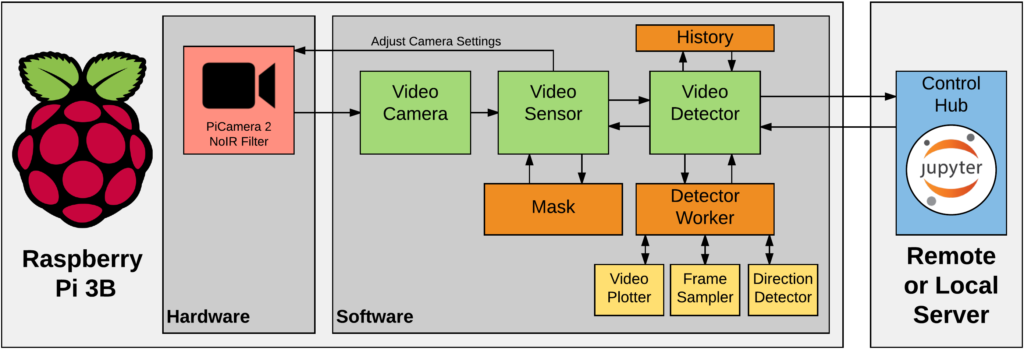
The image above shows the data platform architecture of our Pi train detector. On our Raspberry Pi 3B, our pipeline consists of hardware and software running on top of Raspbian Jesse, a derivative of Debian Linux. All of the software is written in Python 2.7 and can be controlled from a Jupyter Notebook run locally on the Pi or remotely on your laptop. Highlighted in green are our three major components for acquiring, processing, and evaluating streaming video:
- Video Camera: Initializes PiCamera and captures frames from the video stream.
- Video Sensor: Processes the captured frames and dynamically varies video camera settings.
- Video Detector: Determines motion in specified Regions of Interest (ROIs), and evaluates if a train passed.
In addition to our main camera, sensor, and detector processes, several subclasses (orange) are needed to perform image background subtraction, persist data, and run models:
- Mask: Performs background subtraction on raw images, using powerful algorithms implemented in OpenCV 3.
- History: A pandas DataFrame that is updated in real time to persist and access data.
- Detector Worker: Assists the video detector in evaluating image, motion and history data. This class consists of several modules (yellow) responsible for sampling frames from the video feed, plotting data and running models to determine train direction.
Binary Classification
Caltrain detection, at its simplest, boils down to a simple question of binary classification: Is there a train passing right now? Yes or no.
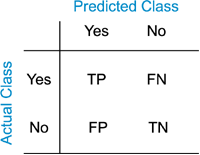
As with any other binary classifier, the performance is defined by evaluating the number of examples in each of four cases:
- Classifier says there is a train and there is a train, True Positive
- Classifier says there is a train when there is none, False Positive
- Classifier says there is no train when there is one, False Negative
- Classifier says there is no train when there isn’t one, True Negative
For more information on classifier evaluation, check out this work by Tom Fawcett.
After running our minimum viable Caltrain detector for a week, we began to understand how our classifier performed, and importantly, where it failed.
Causes of false positives:
- Delivery trucks
- Garbage trucks
- Light rail
- Freight trains
Darkness is the main causes of false negatives.
Our classifier involves two main parameters set empirically: motion and time. We first evaluate the amount of motion in selected ROIs. This is done at five frames per second. The second parameter we evaluate is motion over time, wherein a set amount of motion must occur over a certain amount of time to be considered a train. We set our time threshold at two seconds, since express trains take about three seconds to pass by our sensor located 50 feet from the tracks. As you can imagine, objects like humans walking past our IoT device will not create large enough motion to trigger a detection event, but large objects like freight trains or trucks will trigger a false positive detection event if they traverse the video sensor ROIs over two seconds or more. Future blog posts will discuss how we integrate audio and image classification to decrease false positive events.
While our video classifier worked decently well at detecting trains during the day, we were unable to detect trains (false negatives) in low light conditions after sunset. When we tried additional computationally expensive image processing to detect trains in low light on the Raspberry Pi, we ended up processing fewer frames per second than we captured, grinding our system to a halt. We have been able to mitigate the problem somewhat by using the NoIR model of the Pi camera, which lets more light in during low light conditions, but the adaptive frame rate functionality on the camera didn’t have sufficient dynamic range out of the box.
To truly understand image classification and dynamic camera feedback, it is helpful to understand the nuts and bolts of video processing on a Raspberry Pi. We’ll now walk through some of those nuts and bolts—note that we include the code as we go along.
PiCamera and the Video_Camera class
The PiCamera package is an open source package that offers a pure Python interface to the Pi camera module that allows you to record image or video to file or stream. After some experimentation, we decided to use PiCamera in a continuous capture mode, as shown below in the initialize_camera and initialize_video_stream functions.
class Video_Camera(Thread):
def __init__(self,fps,width,height,vflip,hflip,mins):
self.input_deque=deque(maxlen=fps*mins*60)
#...
def initialize_camera(self):
self.camera = pc.PiCamera(
resolution=(self.width,self.height),
framerate=int(self.fps))
#...
def initialize_video_stream(self):
self.rawCapture = pc.array.PiRGBArray(self.camera, size=self.camera.resolution)
self.stream = self.camera.capture_continuous(self.rawCapture,
format="bgr",
use_video_port=True)
def run(self):
#This method is run when the command start() is given to the thread
for f in self.stream:
#add frame with timestamp to input queue
self.input_deque.append({
'time':time.time(),
'frame_raw':f.array})
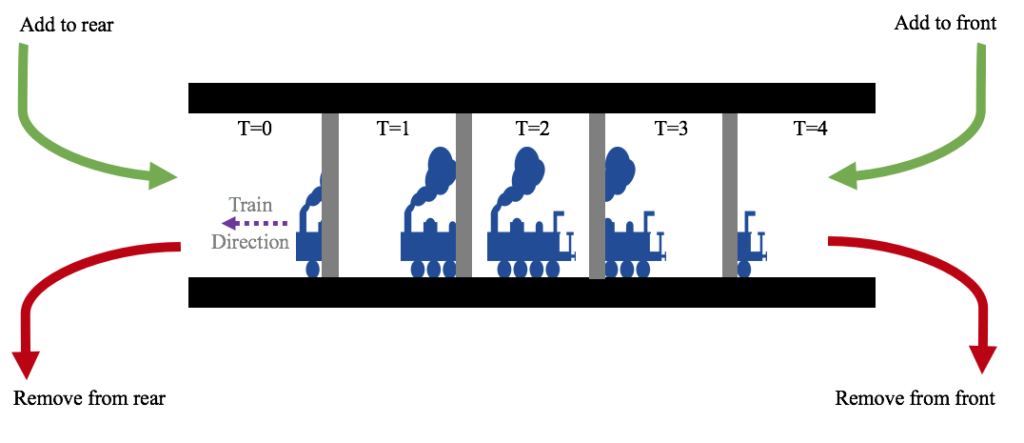
The camera captures a stream of still image RGB pictures (frames). The individual frames are then output as a NumPy array representation of the image. (Note: Careful readers might notice that the format saved is actually BGR, not RGB, because OpenCV uses BGR for historical reasons.) This image is then placed into the front deque, a double-ended queue, for future processing (as shown below). By placing the image into a deque, we can just as quickly access recently taken images from the front of the deque as older images from the rear. Moreover, the deque allows calculation of motion over several frames, and enforces a limit on the total images stored in memory via the maxlen argument. By constraining the length of the deque we minimize the memory footprint of this application. This is important, as the Raspberry Pi 3 only has 1 GB of memory.
Threading and task management in Python
As you may have noticed, the Video_Camera class subclasses a thread from the Python threading module. In order to perform real time train detection on a Raspberry Pi, threading is critical to ensure robust performance and minimize data loss in our asynchronous detection pipeline. This is because multiple threads within a process (our Python script) share the same data space with the main thread, facilitating:
- Communication of information between threads.
- Interruption of individual threads without terminating the entire application.
- Most importantly, individual threads can be put to sleep (held in place) while other threads are running. This allows for asynchronous tasks to run without interruption on a single processor, as shown in the image below.
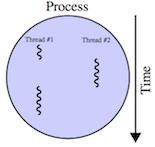
For example, imagine you are reading a book but are interrupted by a freight train rolling by your office. How would you be able to come back and continue reading from the exact place where you stopped? One option is to record the page, line, and word number. This way your execution context for reading a book are these three numbers. If your coworker is using the same technique, she can borrow the book and continue reading where she stopped before. Similar to reading a book with multiple people, or asynchronously processing video and audio signals, many tasks can share the same processor on the Raspberry Pi.
Real time background subtraction and the Video_Sensor class
Once we were collecting and storing data from the PiCamera in the input_deque, we created a new thread, the Video_Sensor, which asynchronously processes these images independent of the Video_Camera thread. The job of the Video_Sensor is to determine which pixels have changed values overtime, i.e. motion. To do this, we needed to identify the background of the image, the non-moving objects in the frame, and the foreground of the image: i.e. the new/moving objects in the frame. After we identified motion, we applied a 5×5 pixel kernel filter to reduce noise in our motion measurement via the cv2.morphologyEx function.
class Video_Sensor(Thread):
def __init__(self,video_camera,mask_type):
#...
def apply_mask_and_decrease_noise(self,frame_raw):
#apply the background subtraction mask
frame_motion = self.mask.apply(frame_raw)
#apply morphology mask to decrease noise
frame_motion_output = cv2.morphologyEx(
frame_motion,\
cv2.MORPH_OPEN,\
kernel=np.ones((2,2),np.uint8))
return frame_motion_output
Real time background subtraction masks
Chloe’s post demonstrated that we could detect trains with processed video feeds that isolate motion, through a process called background subtraction, by setting thresholds for the minimum intensity and duration of motion. Since background subtraction must be applied to each frame and the Pi has only modest computational speed, we needed to streamline the algorithm to reduce computational overhead.
Luckily, OpenCV 3 comes with multiple open source packages that were contributed by the OpenCV community (their use also requires installing opencv_contrib). These include background subtraction algorithms that run optimized C code with convenient Python APIs:
- backgroundsubtractorMOG2: A Gaussian Mixture-based Background/Foreground Segmentation algorithm developed by Zivkovic and colleagues. It uses a method to model each background pixel by an optimized mixture of K Gaussian distributions. The weights of the mixture represent the time proportions that those colors stay in the scene. The probable background colors are the ones which stay longer and are more static.
- backgrounsubtractorKNN: KNN involves searching for the closest match of the test data in the feature space of historical image data. In our case, we are trying to discern large regions of pixels with motion and without motion. An example of this is below, where we try and discern which class (blue square or red triangle) the new data (green circle) belongs to by factoring in not only the closest neighbor (red triangle), but the proximity threshold of k-nearest neighbors. For instance, if k=2 then the green circle would be assigned the red triangle (the two red triangles are closest); but if k=6 then the blue square class would be assigned (the closest 6 objects are 4 blue squares and only 2 red triangles). If tuned correctly, KNN background subtraction should excel at detecting large areas of motion (a train) and should reduce detection of small areas of motion (a distant tree fluttering in the wind).
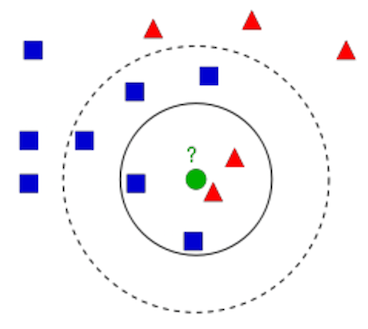
We tested each and found that backgroundsubtractorKNN gave the best balance between rapid response to changing backgrounds, robustly recognizing vehicle motion, and not being triggered by swaying vegetation. Moreover, the KNN method can be improved through machine learning, and the classifier can be saved to file for repeated use. The cons of KNN include artifacts from full field motion, limited tutorials, incomplete documentation, and that backgroundsubtractorKNN requires OpenCV 3.0 and higher.
class Mask():
def __init__(self,fps):
#...
def make_KNN_mask(self,bgsKNN_history,bgsKNN_d2T,bgsKNN_dS):
mask = cv2.createBackgroundSubtractorKNN(\
history=bgsKNN_history,\
dist2Threshold=bgsKNN_d2T,\
detectShadows=bgsKNN_dS)
return mask
Dynamically update camera settings in response to varied lighting
The PiCamera does a great job at adjusting its exposure settings throughout the day to small changes, but it has limited dynamic range, which causes it to struggle with limited illumination at night. Below you can see the motion we detected from our sensor over 24 hours, where the spikes correspond to moving objects like a CalTrain.
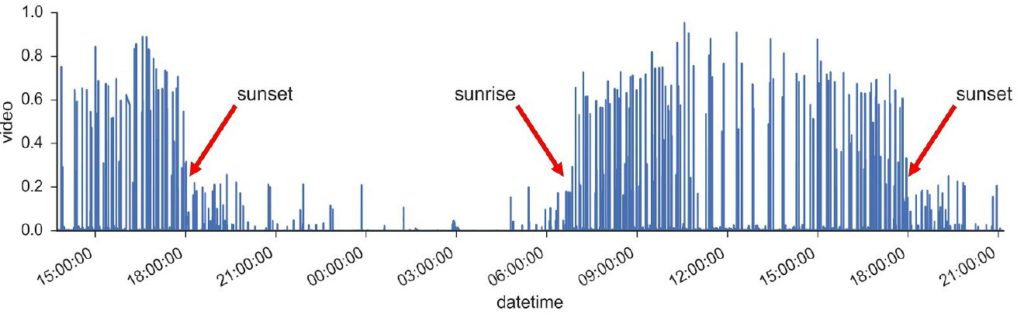 If we were using a digital camera or phone, we could manually change the exposure time or turn on a flash to increase the motion we could capture post sunset or before the sunrise. However, with an automated IoT device, we must dynamically update the camera settings in response to varied lighting. We also picked a night-vision compatible camera without an infrared (IR) filter to gather more light in the ~700-1000 nm range, where normal cameras only capture light from ~400-700 nm. This extra far-to-infrared light is why some of our pictures seem discolored compared to traditional cameras.
If we were using a digital camera or phone, we could manually change the exposure time or turn on a flash to increase the motion we could capture post sunset or before the sunrise. However, with an automated IoT device, we must dynamically update the camera settings in response to varied lighting. We also picked a night-vision compatible camera without an infrared (IR) filter to gather more light in the ~700-1000 nm range, where normal cameras only capture light from ~400-700 nm. This extra far-to-infrared light is why some of our pictures seem discolored compared to traditional cameras.
We found that through manual tuning, there were exposure parameters that allowed us to detect trains after sunset (aka night mode), but we had to define a routine to do automated mode switching.
In order to know when to change the camera settings, we record the intensity mean of the image, which the camera tries to keep around 50% max levels at all times (half max = 128, i.e. half of the 8 bit 0-255 limit). We observed that after sunset, the mean intensity dropped below ~1/16 of max, and we were unable to reliably detect motion. So we added a feature to poll the mean intensity periodically, and if it fell below 1/8th of the maximum, the camera would adjust to night mode. Similarly, the camera would switch back to day mode if the intensity was greater than 3/4th of the maximum.
After we change the camera settings, we reset the background subtraction mask to ensure that we did not falsely trigger train detection. Importantly, we wait one second between setting camera settings and triggering the mask, to ensure the camera thread is not lagging and has updated before the mask is reset.
class Video_Sensor(Thread):
#...
def vary_camera_settings(self,frame_raw):
intensity_mean=frame_raw.ravel().mean() #8 bit camera
#adjust camera properties dynamically if needed, then reset mask
if ((intensity_mean < (255.0/8) ) & (self.camera.operating_mode=='day')):
self.video_camera.apply_camera_night_settings()
time.sleep(1)
self.mask=self.mask_object.make_mask(self.mask_type)
print 'Day Mode Activated - Camera'
if ((intensity_mean < (255.0*(3/4)) ) & (self.camera.operating_mode=='night')):
self.video_camera.apply_camera_day_settings()
#...
return intensity_mean,self.mask
Real-time detection of trains with the Video_Detector class
At this point, the video sensor is recording motion in a frame 5 times per second (5 FPS). Next, we needed to create a Video Detector for detecting how long and what direction an object has been moving through the frame. To do this, we created three ROIs in our frame that the train passes through. By having three ROIs, we can see if a train enters from the left (southbound) or right (northbound). We found that having a third center ROI decreases the effect of noise in an individual ROI, thereby improving our ability to predict train directionality and more accurately calculate speed.
We then created a circular buffer to store when individual ROIs have exceeded the motion threshold. The length of this motion_detected_buffer is set as the minimum time corresponding to a train, multiplied by the camera FPS (we set this as two seconds; the motion_detected_buffer has a length of ten). We added logic to our Video_Detector class that prevents a train from being detected more than once in cool-down period, to prevent slow moving trains as being registered as a train more than one time. Additionally, we used a frame sampling buffer to keep a short term record of raw and processed frames for future analysis, plotting or saving.
Using all of these buffers, the Video_Detector class creates ROI_to_process, which is an array of information which stores time, the motion from the three ROIs, if motion was detected, and the direction of the train motion. The video below shows the normal video of the train passing, and the background subtracted versions (MOG2 in the middle pane, KNN in the right pane).
def run(self):
self.framenum=0
while self.kill_all_threads!=True:
data=self.output_deque.popleft()
#...
#update the history dataframe and adjust the frame number pointer
self.history.iloc[self.framenum % self.history.shape[0]] = self.roi_data
self.framenum+=1
#add frames and data to sampler
self.frame_sampler_buffer.append({
#...
Persist processed data to pandas DataFrame
With relevant train sensor and detector data stored in memory, we chose to use pandas DataFrames to persist this data for future analysis. Pandas is a Python package that provides fast and flexible data structures designed to work efficiently with both relational and labeled data. Similar to using SQL for managing data held in relational database management systems (RDBMS), pandas makes importing, querying and exporting data easy.
We used the History class to create a DataFrame that loads time, sensor, and processed detector data. Since the Pi has limited memory, we implemented the History DataFrame as a limited length circular buffer to prevent memory errors.
class History():
def __init__(self,fps):
self.len_history=int(fps*600)
self.columns=['time','left_roi','middle_roi','right_roi',\
'motion_detected','train_detected','direction']
def setup_history(self):
#create pandas dataframe that contains column information
self.history = pd.DataFrame.from_records(\
np.zeros((self.len_history,len(self.columns))),
index=np.arange(self.len_history),
columns=self.columns)
#...
This allowed us to easily retrieve and analyze train detection events. Shown below is 17 frames (3.4 seconds of data at 5 FPS) of data of a northbound Caltrain.
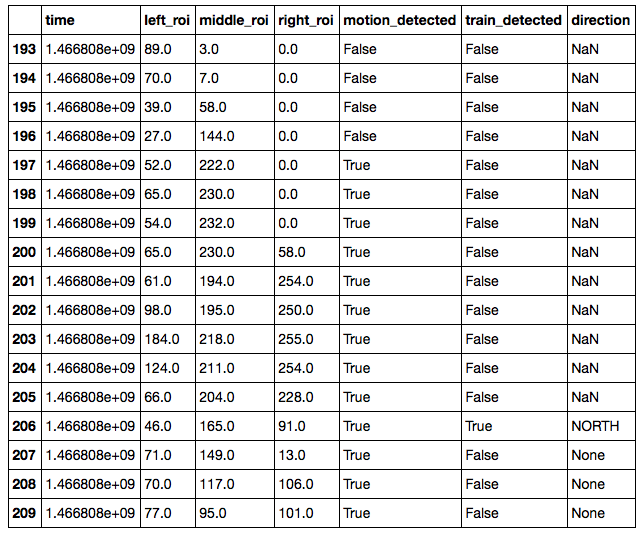
Detector_Worker class
Once we were persisting data in a DataFrame, we visualized the raw sensor and processed detector data. This required additional processing time and resources, and we did not want to interrupt the video detector. We therefore used threading to create the Detector_Worker class. The Detector_Worker is responsible for plotting video, determining train direction, and returning sampled frames to the Jupyter notebook or file system. Shown below is the output of the video plotter. On the top left is one raw frame of video, and on the bottom right is one KNN-background-subtracted motion frame. The two right frames have the three ROIs overlaid onto the image.
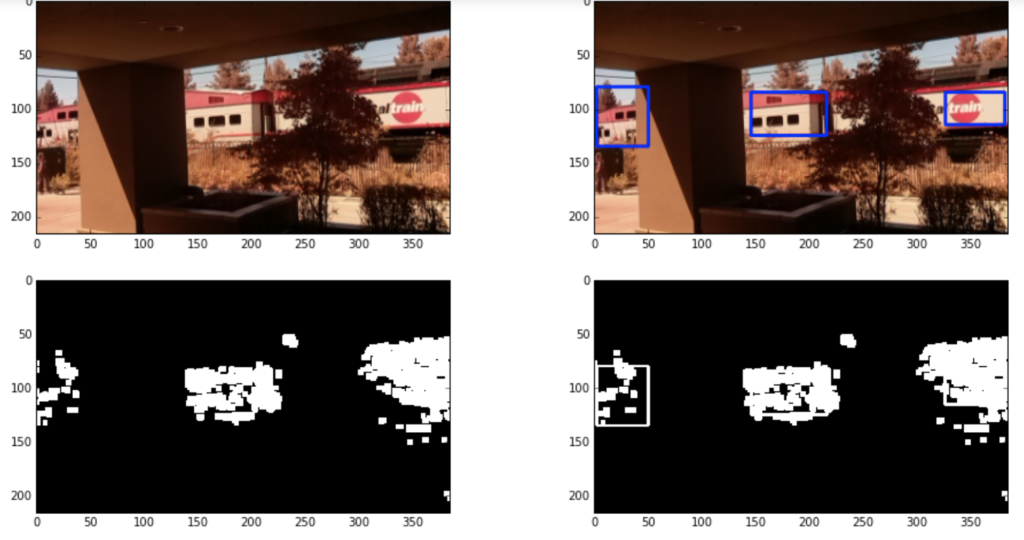
Train direction
The last step was to deduce train direction. In order to accurately detect train direction within our streaming video analysis platform, we iterated through several methods.
- Static ‘Boolean’ Method: Track motion level in each individual ROIs and then select north/south depending on which ROI exceeded the threshold first. We found that this static boolean method does not work well for express trains which triggered the north and south facing detectors simultaneously when using low framerates.
- Streaming ‘Integration’ Method: This method involved summing the historical levels motion in each ROI, and determining direction by which ROI had the highest sum. We found that this method was too reliant on accurate setting of ROI position, and broke down if the camera was ever moved. The problem this created was that if an ROI never became fully saturated with motion, the maximum mean intensity it could reach for a true positive could be lower than the mean of an ROI due to non-train motion.
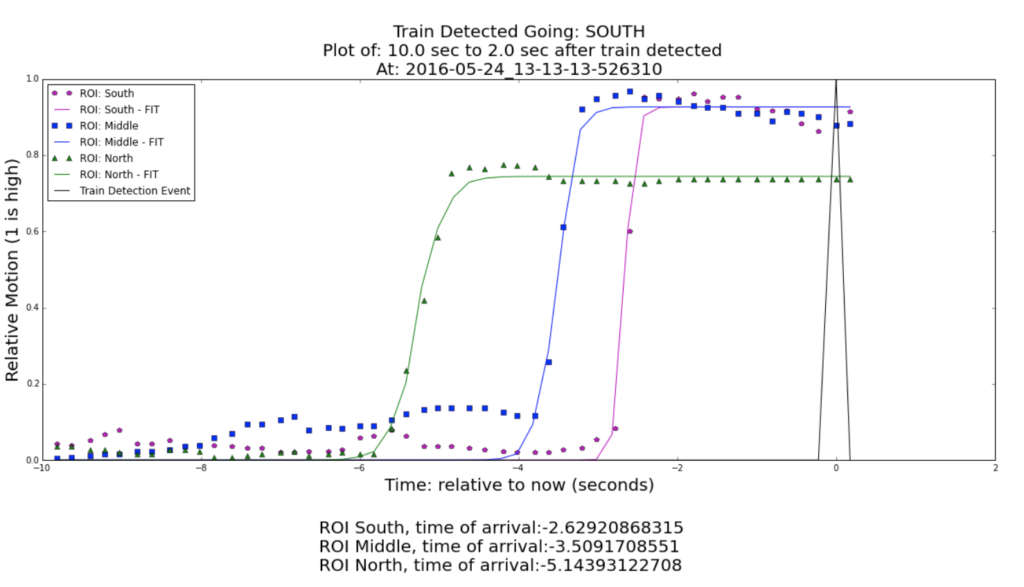
- Streaming ‘Curve-Fit’ Method: We next tried to combine the boolean and integration method with a simple sigmoid model of motion across the frame. If average motion across the three ROIs exceeded our motion threshold, we empirically fit a sigmoid curve to determine when the train passed in time (i.e. at 50% max motion). If the data was noisy and curve fitting failed, we revert back to the static boolean method. Moreover, our curve-fit method allows determination of train speed if the real distance between the ROIs is known.
class Detector_Worker(Thread):
def curve_func(self,x, a, b,c):
#Sigmoid function
return -a/(c+ np.exp(b * -x))
#...
def alternate_km_map(self,ydata,t,event_time):
#determine emperically where the ROI sensor hits 50% of the max value
max_value = max(ydata)
for i in range(0,len(ydata)):
#if the value is above half of the max value
if ydata[i] > max_value/2.0:
km=t[i]-event_time
return km
#if the value never exceeds half of the max value
#return the end of the time series
km=t[-1]-event_time
return km
Below is an example of a local southbound train passing our Mountain View office. If you’d like to learn more about analyzing time series data, please see Tom Fawcett’s post on avoiding common mistakes with time series data.
Conclusion
You should now have an idea of how to design your own architecture for stream video processing on an IOT device. We will cover more of this project in future posts, including determination of train speed. Importantly, other false positives like light rails or large trucks that pass in front of the camera also trigger the sensor. By having a secondary data feed, i.e. audio, we can have a second input to determine if a train is passing by both visual and audio cues.
Later in the Trainspotting series we will also cover how to reduce false positive of freight trains using image recognition. Keep an eye out for future posts in our series, and let us know below if there’s something in particular you’d like to learn about.