
Flexible Data Architecture with Spark, Cassandra, and Impala
September 30th, 2014
Overview
An important aspect of a modern data architecture is the ability to use multiple execution frameworks over the same data. By using open data formats and storage engines, we gain the flexibility to use the right tool for the job, and position ourselves to exploit new technologies as they emerge.
This article will demonstrate the use of two separate storage engines, HDFS and Cassandra, coupled with multiple execution frameworks, including Spark, Spark Streaming, Spark SQL, Impala, and CQL. Kafka will be used for scalable fault tolerant data ingestion.
The ideal scenario would be a single copy of the data to serve all our data needs, but this is very difficult to achieve because the underlying architectures that serve high-volume, low-latency OLTP needs are fundamentally different from those needed to serve the large table scans required in analytical use cases. For example, Cassandra purposely makes it difficult to be able to scan large ranges of data, but allows for low-millisecond access of millions of records per second. On the flip side, the fundamental storage pattern in distributed file systems like HDFS purposely does not index data to allow for low-millisecond access, but uses larger block sizes to allow for very fast sequential access of data to scan billions of records per second.
Streaming engines like Spark Streaming help mitigate the problem by allowing analytics to be performed on the fly as data is ingested into the system. But when is the last time you were able to predict every metric that needed to be calculated at project inception? Thus lambda architectures have arisen to allow metrics to be added down the road by recomputing history.
One important characteristic of a good lambda architecture is that the system needing to re-compute history should be able to operate quickly on a large dataset without disrupting performance or the low-latency user traffic. Therefore, in this example we have chosen to store that copy of our data in Parquetformat on HDFS, whereas for the low-latency user traffic, the example uses Cassandra.
Setup
For the setup I am using the following existing deployments:
- Datastax 4.0.3 (Cassandra 2.0.7.31)
- CDH5.1 HDFS and Impala
- Kafka 0.8.1.1 built for Scala 2.10
- Spark 1.1 built for Hadoop 2.3
- Java 7
Installation Notes
- At the time of writing, earlier versions of Spark were bundled with both CDH 5.1 and Datastax 4.5, but I needed capabilities only available in Spark 1.1 and I had a pre-Datastax 4.5 cluster, so I installed Spark separately.
- To expedite examples a single node deployment was used, but each feature has been run on multi-node environments as well.
- Make sure that the Spark master hostname is the first entry in /etc/hosts to mitigate bind issues.
- The following list of jars were needed to run examples: cassandra-all-2.0.7.31.jar, cassandra-thrift-2.0.7.31.jar, libthrift-0.9.1.jar, cassandra-driver-core-2.0.1.jar, cassandra-driver-dse-2.0.1.jar, spark-cassandra-connector_2.10-1.1.0-SNAPSHOT.jar, dse.jar, high-scale-lib-1.1.2.jar, treehugger_2.10-0.2.3.jar, kafka_2.10-0.8.1.1.jar, spark-streaming-kafka_2.10-1.1.0.jar, zkclient-0.3.jar, metrics-core-2.2.0.jar,joda-time-2.4.jar
- All of the jars above were available for download except for spark-cassandra-connector_2.10-1.1.0-SNAPSHOT.jar, which I built using these instructions.
Example Description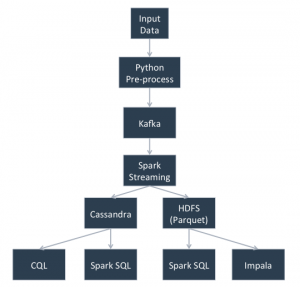
- This scenario will start with a python script that will read an example document (my colleague, Edd Dumbill’s article on The Experimental Enterprise).
- The python script will publish the data to Kafka.
- A continuously running Spark Streaming job will read the data from Kafka and perform a word count on the data.
- The Spark Streaming job will write the data to Cassandra.
- The Spark Streaming job will write the data to a parquet formatted file in HDFS.
- We can then read the data from Spark SQL, Impala, and Cassandra (via Spark SQL and CQL).
Create Kafka Topic:
kafka-topics.sh --create --topic demo --zookeeper localhost:2181 --partitions 1 --replication-factor 1
Start spark-shell with needed jars:
~/spark-1.1.0-bin-hadoop2.3/bin/spark-shell --jars cassandra-all-2.0.7.31.jar,cassandra-thrift-2.0.7.31.jar,libthrift-0.9.1.jar,cassandra-driver-core-2.0.1.jar,cassandra-driver-dse-2.0.1.jar,spark-cassandra-connector_2.10-1.1.0-SNAPSHOT.jar,dse.jar,high-scale-lib-1.1.2.jar,treehugger_2.10-0.2.3.jar,kafka_2.10-0.8.1.1.jar,spark-streaming-kafka_2.10-1.1.0.jar,zkclient-0.3.jar,metrics-core-2.2.0.jar,joda-time-2.4.jar
Execute Spark code:
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import com.datastax.spark.connector._
import com.datastax.spark.connector.streaming._
import com.datastax.bdp.spark.SparkContextCassandraFunctions._
import com.datastax.bdp.spark.RDDCassandraFunctions._
//Change logging level to WARN
import org.apache.log4j.Logger
import org.apache.log4j.Level
Logger.getLogger("org").setLevel(Level.WARN)
Logger.getLogger("akka").setLevel(Level.WARN)
//Add Cassandra connection configuration to spark context
val conf = new SparkConf()
conf.set("cassandra.connection.host", "localhost")
val sc = new SparkContext(conf)
//Create a Streaming Context with batch interval of 60 seconds
val ssc = new StreamingContext(sc, Seconds(60))
//Add spark sql context
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext._
//Create input stream from kafka
val lines = KafkaUtils.createStream(ssc, "localhost:2181", "demo", Map("demo" -> 10)).map(_._2)
//Split each line into words
val words = lines.flatMap(_.split(" "))
//Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
//Case class is used to assign column names
case class W(key: String, value: Int)
//Iterate over RDDs in batch - rdd ids are used to partition for simple example, but normally data would be partitioned by time
wordCounts.foreachRDD(rdd => {
//Re-partition data to balance cassandra load
val rdd2 = rdd.repartition(8)
//Load data into Cassandra
rdd2.saveToCassandra("test", "word", Seq("key", "value"))
//Load data into parquet files partitioned by rdd
val rdd3 = rdd2.map(b => W(b._1,b._2))
rdd3.saveAsParquetFile("hdfs://localhost:8020/tmp/wc/rdd=" + rdd3.id)
})
//Start streaming process
ssc.start()
ssc.awaitTermination()
Python code to add data to kafka:
I added basic optional logic here to do NLP on the text like stemming and removing stop words using NLTK, but not necessary for non-text workloads in which records can be sent directly to kafka without any pre-processing.
Install python dependencies:
pip install kafka-python
pip install nltk
python -m nltk.downloader stopwords -d ~/nltk_data
python -m nltk.downloader punkt -d ~/nltk_data
Then open python shell and execute this on your given ascii file (test.txt) containing several words:
from kafka.client import KafkaClient
from kafka.producer import SimpleProducer
kafka = KafkaClient("localhost:9092")
producer = SimpleProducer(kafka, batch_send=True,batch_send_every_n=2000,batch_send_every_t=1)
import nltk
import string
from collections import Counter
def get_tokens():
with open('test.txt', 'r') as shakes:
text = shakes.read()
lowers = text.lower()
#remove the punctuation using the character deletion step of translate
no_punctuation = lowers.translate(None, string.punctuation)
tokens = nltk.word_tokenize(no_punctuation)
return tokens
from nltk.corpus import stopwords
tokens = get_tokens()
filtered = [w for w in tokens if not w in stopwords.words('english')]
from nltk.stem.porter import *
def stem_tokens(tokens, stemmer):
stemmed = []
for item in tokens:
stemmed.append(stemmer.stem(item))
return stemmed
stemmer = PorterStemmer()
stemmed = stem_tokens(filtered, stemmer)
for word in stemmed:
producer.send_messages("demo",str(word))
Accessing the Data
Once the data has been processed by spark streaming it can then be accessed in multiple ways.
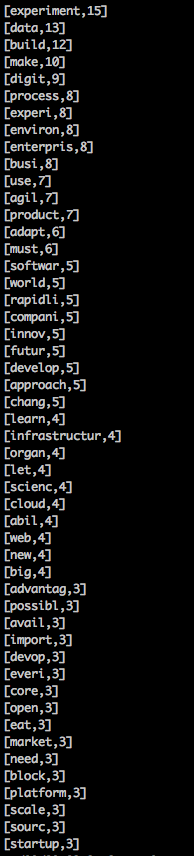
Spark SQL read parquet:
This code snippet shows how to read a given partition of parquet data in HDFS from the spark-shell.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.createSchemaRDD
val parquetFile = sqlContext.parquetFile("hdfs://localhost:8020/tmp/wc/rdd=10")
parquetFile.registerAsTable("test")
sqlContext.sql("cache table test")
sqlContext.sql("select * from test order by value desc limit 50").foreach(println)
Results:
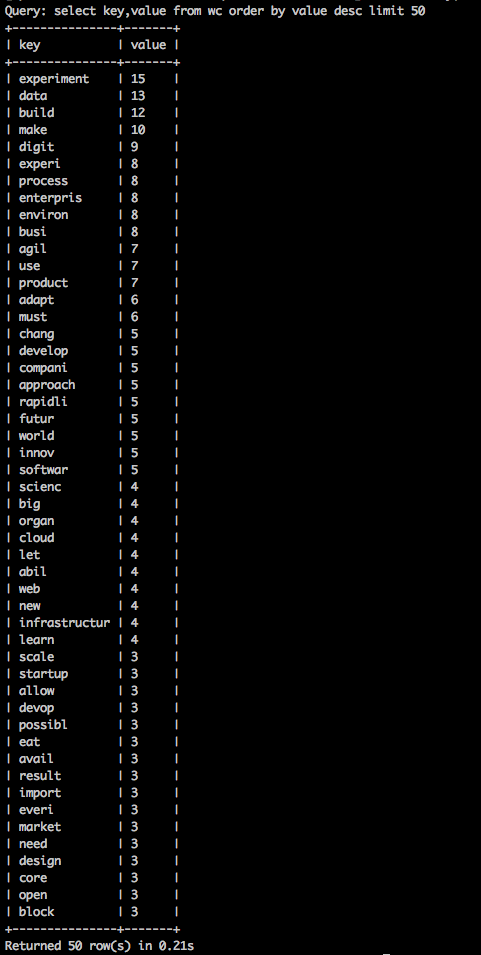
Impala read parquet:
This code snippet shows how to read a given partition of parquet data in HDFS from Impala.
create EXTERNAL TABLE wc LIKE PARQUET '/tmp/wc/rdd=10/_metadata' PARTITIONED BY (rdd int) stored as parquet LOCATION '/tmp/wc'; alter table wc add partition (rdd=10); select key,value from wc order by value desc limit 50;
Results:
Cassandra CQL read data:
This query shows how to read data from Cassandra using CQL. Note: with the simple Cassandra table design it was not possible to run order by.
cqlsh:test> select * from word limit 5;
Results:
Cassandra Spark Read Data:
This code snippet shows how to read data from Cassandra from the spark-shell.
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.createSchemaRDD
val conf = new SparkConf()
conf.set("cassandra.connection.host", "localhost")
import com.datastax.bdp.spark.SparkContextCassandraFunctions._
val sc = new SparkContext("local", "Cassandra Connector Test", conf)
case class W(key: String, value: Int)
sc.cassandraTable[W]("test", "word").registerAsTable("word")
sqlContext.sql("cache table word")
sqlContext.sql("select key,value from word order by value desc limit 50").take(50)
Results:
![]()
Conclusion
We have only scratched the surface of how this process can be used to solve multiple data engineering problems. Hopefully this post provides some good working examples of getting these systems playing nicely together. There were several small examples on the web of setting up individual pieces of this data pipeline, but none that I found got them all working together in one place, which had its challenges. I was also unable to find many references on running standalone Spark against a Cassandra cluster, except through the native Datastax deployment starting in 4.5. Hopefully this provides an alternative for some users who are unable to upgrade or have other constraints.



